Spark On Yarn. HDP 2.6.3(Spark2.2,Yarn 2.7.3)
基础
- ExecutionMemory用于spark计算中的shuffles、 joins、sorts 、 aggregations这些操作。
- StorageMemory用于缓存数据和保存广播变量数据 。
- Spark On Yarn,deploy-mode是Client时driver运行在客户端,Cluster时driver和AM在一起。
确定increment
- 检查yarn.resourcemanager.scheduler.class配置,使用的是CapacityScheduler.而只有FairScheduler才会有increment-allocation-mb配置(默认1024,org/apache/hadoop/yarn/server/resourcemanager/scheduler/fair/FairSchedulerConfiguration.java:45)
- CapacityScheduler#allocate(org/apache/hadoop/yarn/server/resourcemanager/scheduler/capacity/CapacityScheduler.java:875)调用SchedulerUtils#normalizeRequests时没有传最后的incrementResource参数
- 下一步SchedulerUtils#normalizeRequests(org/apache/hadoop/yarn/server/resourcemanager/scheduler/SchedulerUtils.java:143)传的incrementResource参数其实是minimumResource,即集群配置minimum-allocation-mb或默认YarnConfiguration#DEFAULT_RM_SCHEDULER_MINIMUM_ALLOCATION_MB的1024(org/apache/hadoop/yarn/server/resourcemanager/scheduler/capacity/CapacitySchedulerConfiguration.java:627)
- 总结:CapacityScheduler的increment是minimum-allocation-mb(默认1024)
默认值
有些在这也有说明https://spark.apache.org/docs/2.2.0/running-on-yarn.html
- spark.driver.memory:默认值1024m(core/org/apache/spark/network/util/JavaUtils.java:50)
- spark.executor.memory:默认值1024m,(core/org/apache/spark/SparkContext.scala:478)
- spark.yarn.am.memory:默认值512m,(resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/config.scala:211)
- spark.yarn.executor.memoryOverhead:值为max(spark.executor.memory * 0.1, 384),源码YarnSparkHadoopUtil#MEMORY_OVERHEAD_FACTOR(resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala:113),下同
- spark.yarn.driver.memoryOverhead:值为max(driverMemory * 0.1, 384)
- spark.yarn.am.memoryOverhead:值为max(AM memory * 0.1, 384)
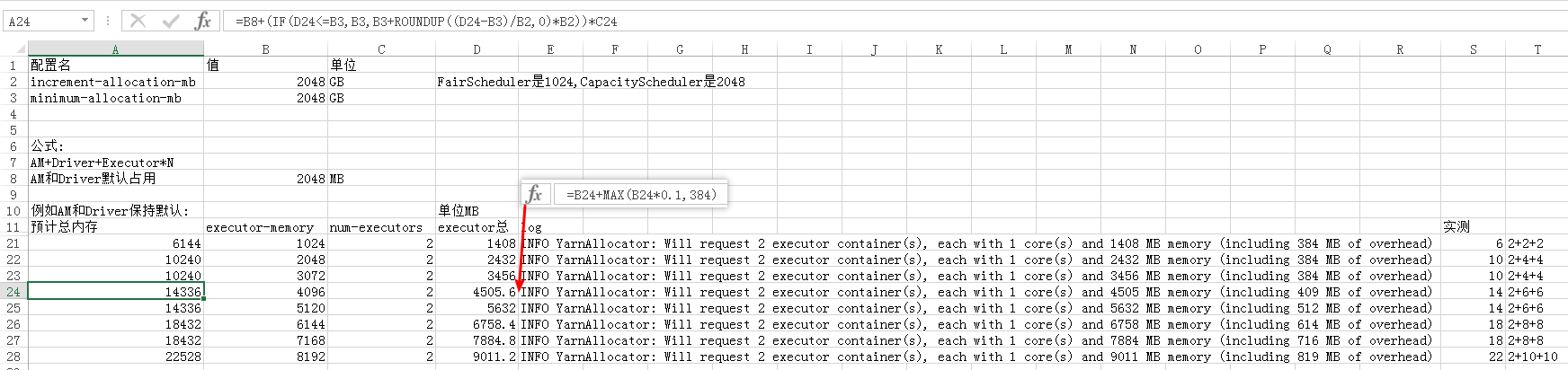
spark on yarn内存计算公式
- spark on yarn申请的container数=${num-executors}+1(AM一个container,每个executor一个container)
- executor需要申请的总内存:total=${executor-memory}+max(${executor-memory}*0.1,384)
- executor所在container实际申请的内存分两种情况:
- total <= yarn.scheduler.minimum-allocation-mb,则实际分配内存大小为yarn.scheduler.minimum-allocation-mb
- total > yarn.scheduler.minimum-allocation-mb,则实际分配内存大小为yarn.scheduler.minimum-allocation-mb+( total-yarn.scheduler.minimum-allocation-mb)取 yarn.scheduler.increment-allocation-mb的整数倍
假设:yarn.scheduler.minimum-allocation-mb=2G,increment=2G,–executor-memory 2G 则:executor所在container实际申请的内存=2G+2G=4G,AM所在executor实际申请内存=2G,总申请内存为6G
计算方法及实测验证见Excel公式:
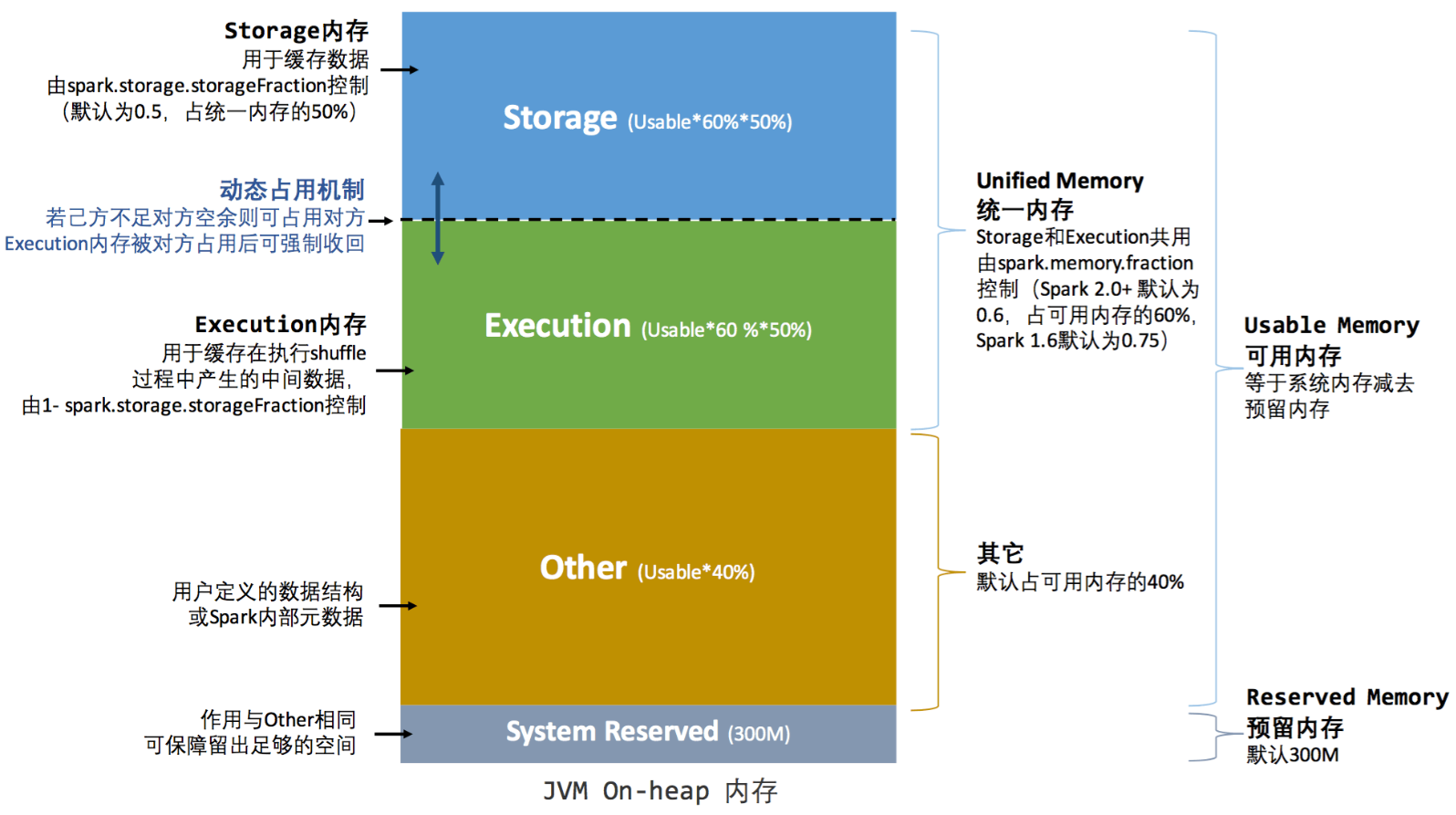
UnifiedMemoryManager
Spark1.6后使用此Manager
- Reserved Memory:300M(core/org/apache/spark/memory/UnifiedMemoryManager.scala:196).这一部分的内存是我们无法使用的部分,spark内部保留内存,会存储一些spark的内部对象等内容。这部分大小是不允许我们使用者改变的。简单点说就是我们在为executor申请内存后,有300MB是我们无法使用的。并且如果我们申请的executor的大小小于1.5 * Reserved Memory 即 < 450MB,spark会报错.
- User Memory:用户在程序中创建的对象存储等一系列非spark管理的内存开销都占用这一部分内存
- Spark Memory:该部分大小为 (JVM Heap Size - Reserved Memory) * spark.memory.fraction(默认0.6. core/org/apache/spark/memory/UnifiedMemoryManager.scala:231).Storage和Execution占比由spark.memory.storageFraction(core/org/apache/spark/memory/UnifiedMemoryManager.scala:204)决定
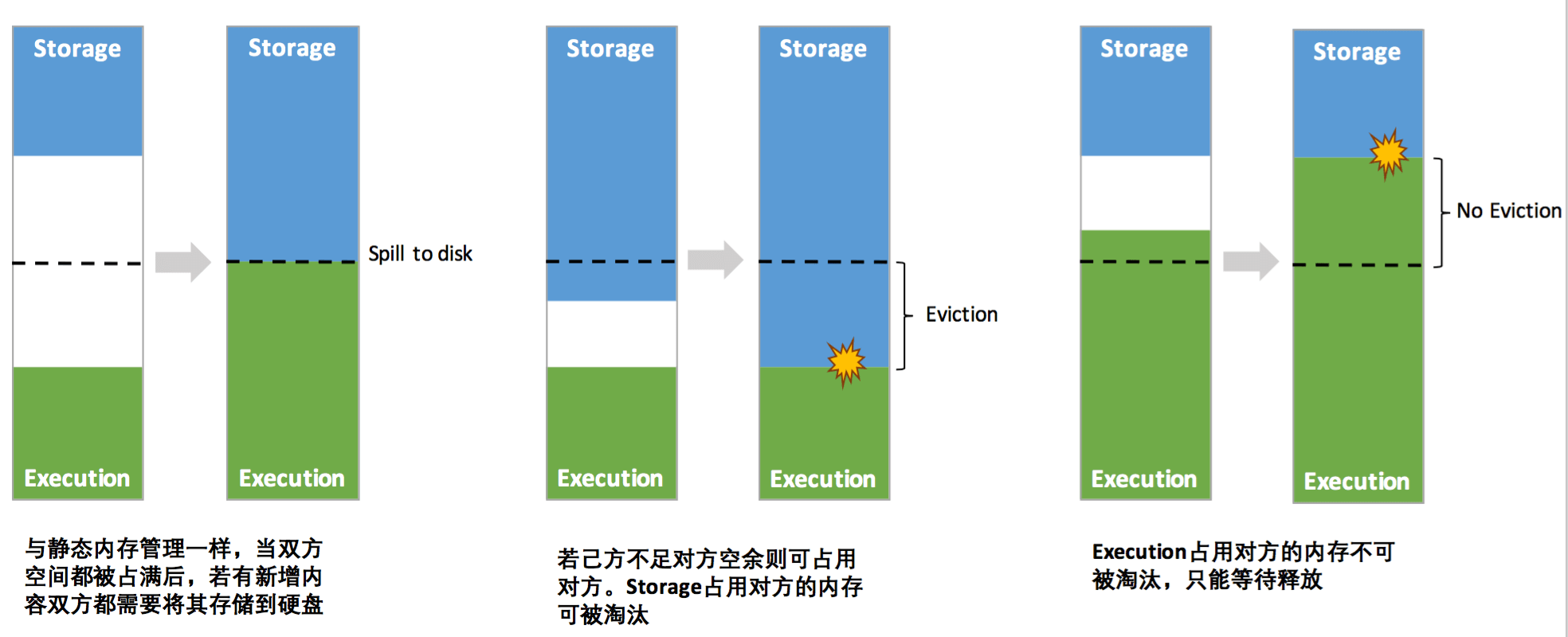
示意图如下:
参考及引用: